Prefer a visual interface? Try the Cloud UI instead. No code required.
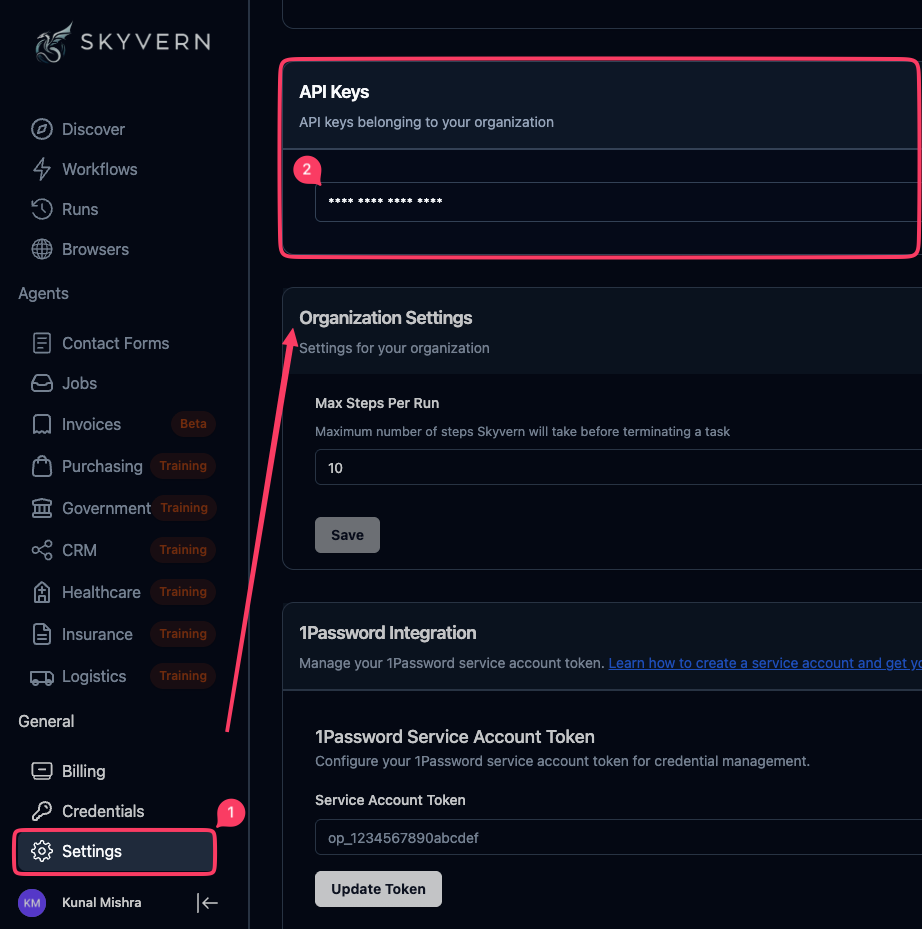
Step 1: Get your API key
Step 2: Install the SDK
Troubleshooting: Python version errors
Troubleshooting: Python version errors
The Skyvern SDK requires Python 3.11, 3.12, or 3.13. If you encounter version errors, try using pipx:pipx installs Python packages in isolated environments while making them globally available.
Step 3: Launch a browser and extract data
When you calllaunch_cloud_browser(), Skyvern spins up a Chromium instance in the cloud. Your code drives that browser via a Playwright Page that also has AI methods (act, extract, validate, prompt) layered on top. You can watch the browser live at any time.
Why
page.extract is enough here. For a one-shot read on a single page, page.extract(prompt, schema=...) returns the extracted data directly (a dict in Python, object in TS). For multi-step goals like “log in, navigate to billing, download the invoice”, use page.agent.run_task(prompt) instead; it runs a full AI task loop on the page and returns a TaskRunResponse. See Build a Browser Automation for the full walkthrough.Step 4: Understand the output
page.extract returns the extracted data as a dict. For the Hacker News example you’ll see something like:
Watch live: ...is printed before any AI calls. Open it in another tab to watch the browser navigate and extract in real time.Extracted: {...}appears afterpage.extractreturns. The key names come from the AI (unless you pass aschema, in which case they match your schema). For typed, predictable output, see Extract Structured Data.
If you used the cURL path
The task API is asynchronous. The POST returns arun_id; poll for the final result:
created,queued: Waiting for an available browserrunning: AI is navigating and executingcompleted: Task finished successfullyfailed/terminated/timed_out/canceled: Non-success terminal states
Step 5: Watch the recording
Every run is recorded. Two ways to access it:Live
While the script runs, theWatch live: ... URL printed in Step 3 streams the browser in real time.
After the run
Open Runs and click on your run to see the Recording tab, step-by-step actions with screenshots, and AI reasoning for each decision.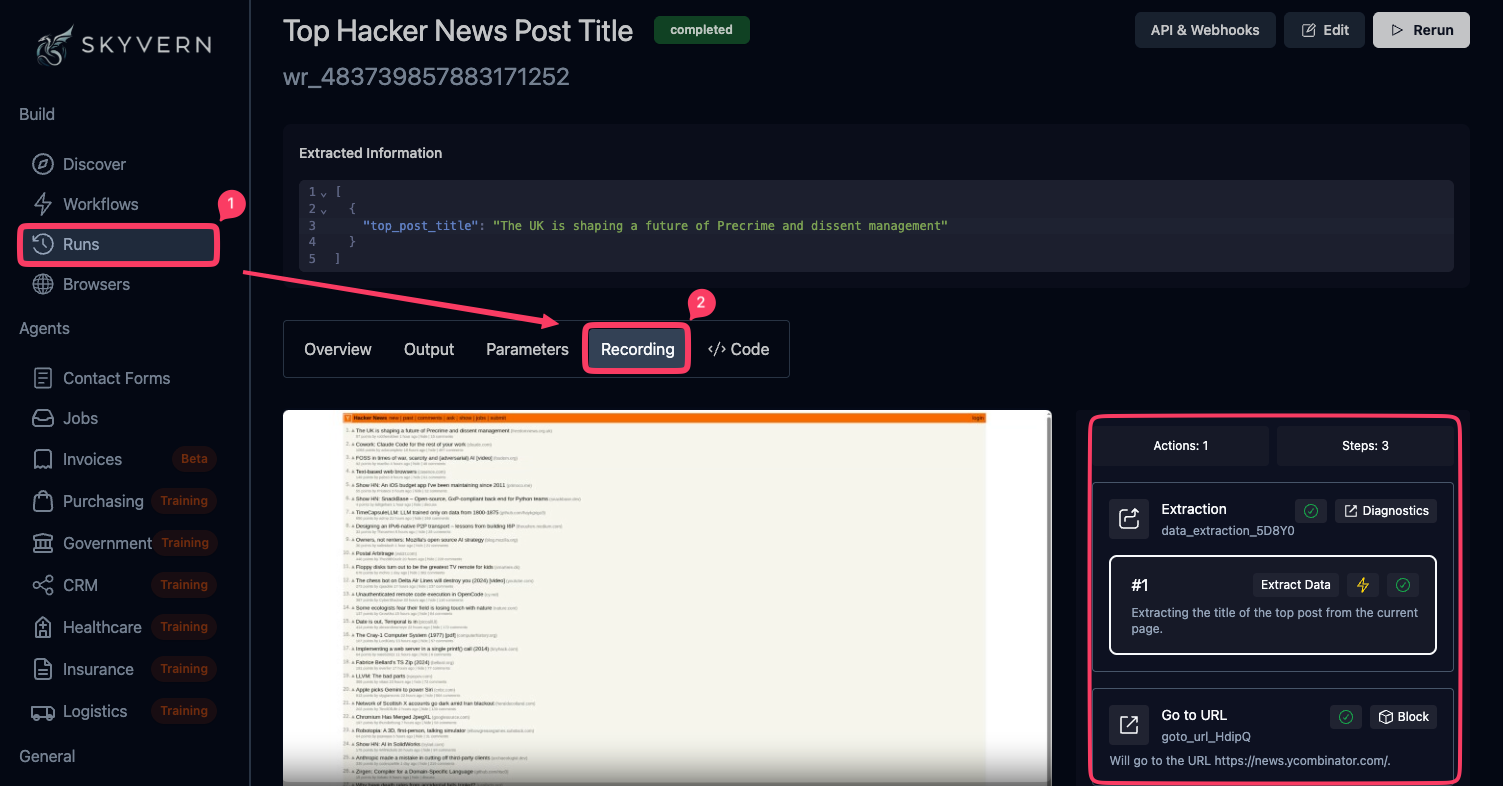
Run with a local browser
You can run Skyvern with a browser on your own machine. This is useful for development, debugging, or automating internal tools on your local network. Prerequisites:- Skyvern SDK installed (
pip install skyvern) - PostgreSQL database (local install or Docker)
- An LLM API key (OpenAI, Anthropic, Azure OpenAI, Gemini, Ollama, or any OpenAI-compatible provider)
Docker is optional. If you have PostgreSQL installed locally, Skyvern will detect and use it automatically. Use
skyvern init --no-postgres to skip database setup entirely if you’re managing PostgreSQL separately.Set up local Skyvern
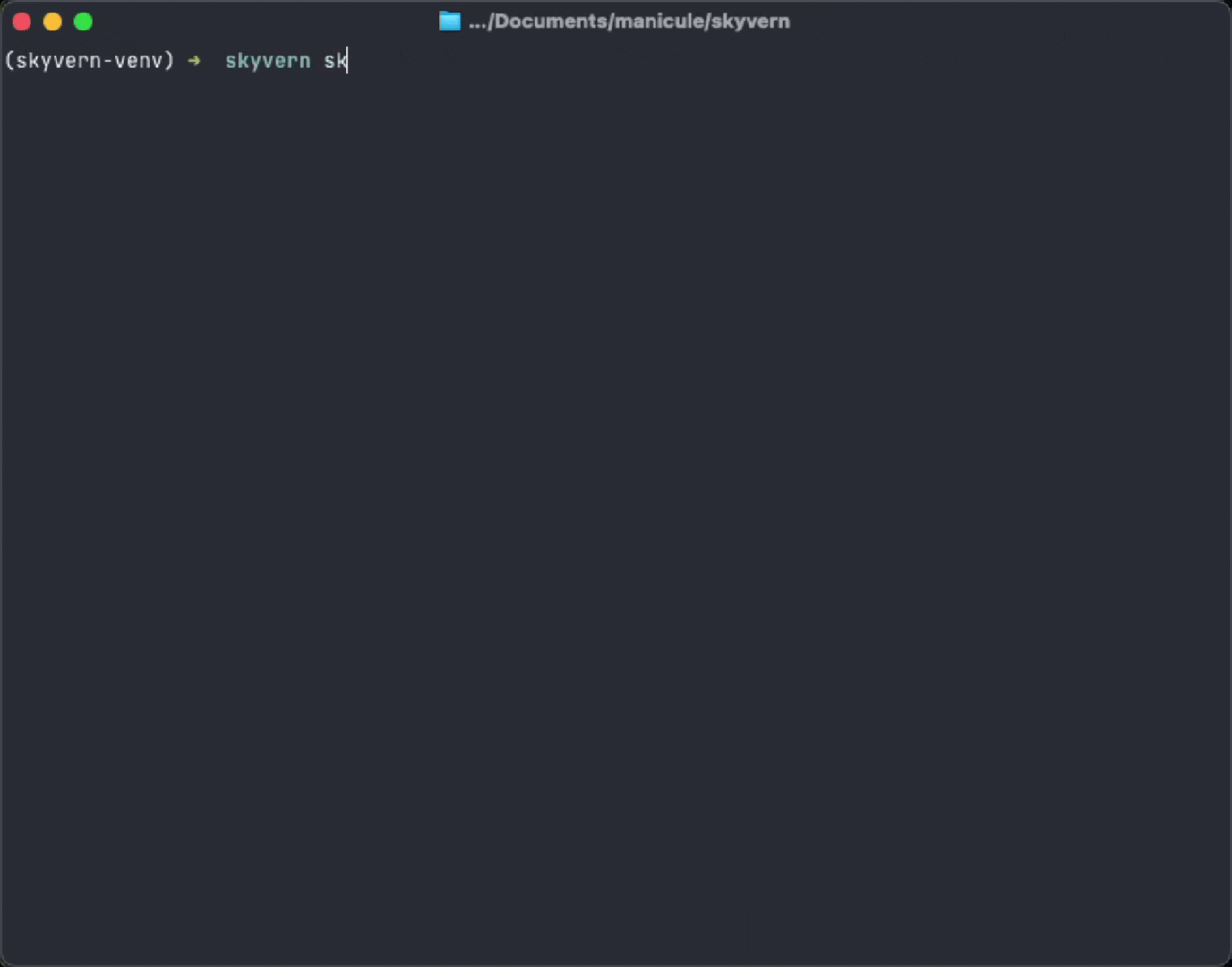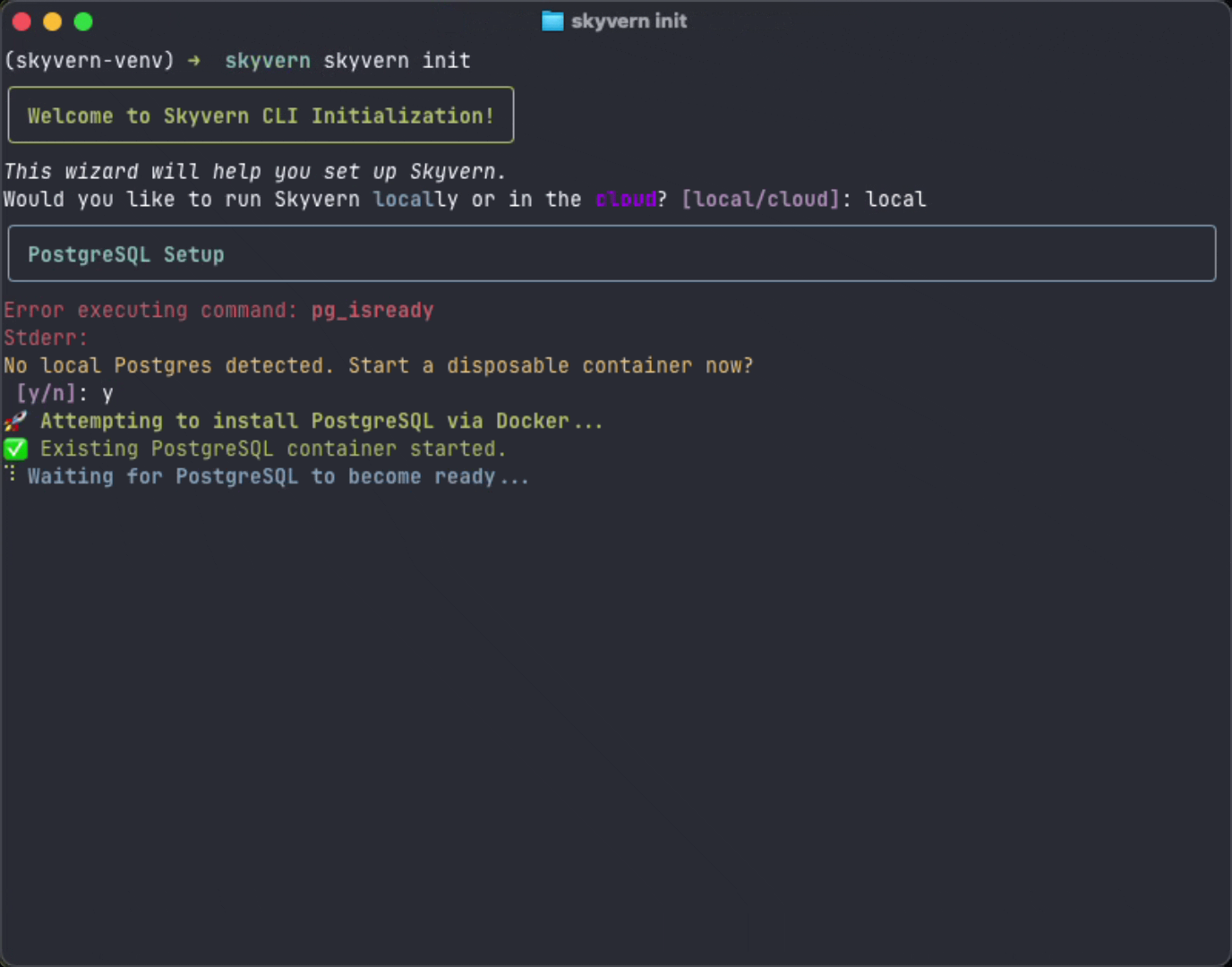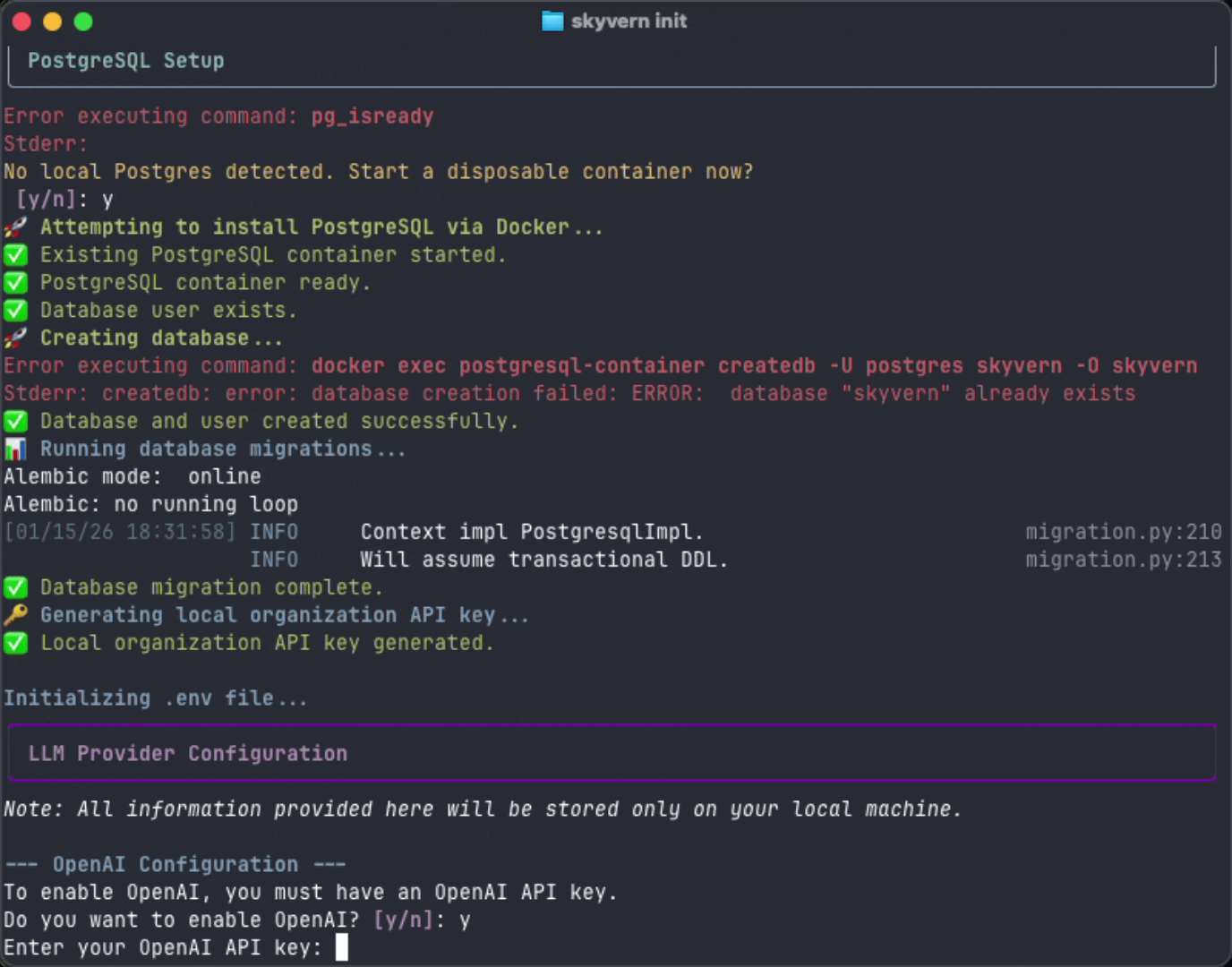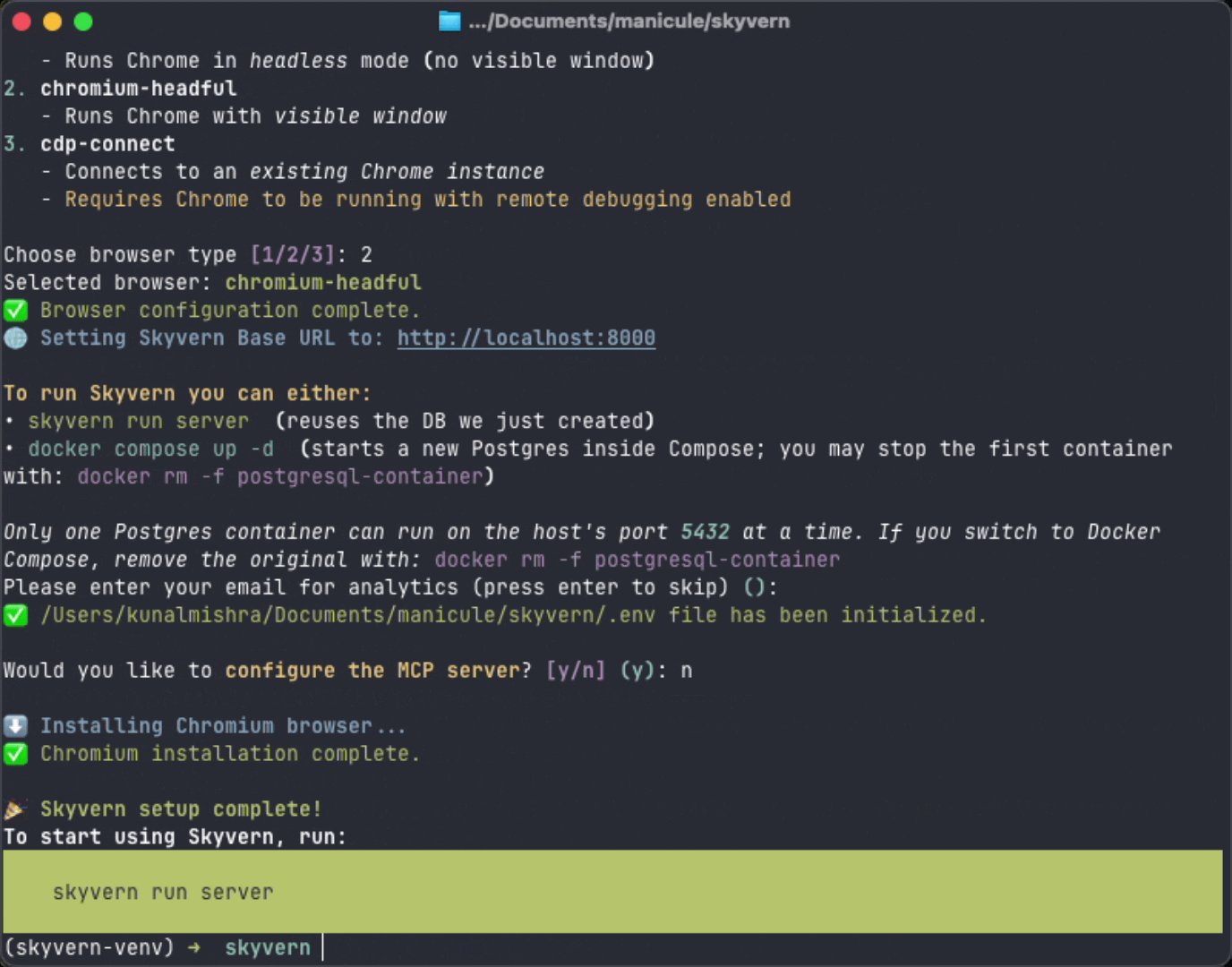
- Set up your database (detects local PostgreSQL or uses Docker)
- Configure your LLM provider
- Choose browser mode (headless, headful, or connect to existing Chrome)
- Generate local API credentials
- Optionally configure local MCP for Claude Code, Claude Desktop, Cursor, or Windsurf
- Download the Chromium browser
- write a project-local
.mcp.json - pin the MCP command to the active Python interpreter (
/path/to/python -m skyvern run mcp) - install bundled Claude Code skills into
.claude/skills/, including/qa - keep the whole path local, so Claude Code can test
localhostdirectly without Skyvern Cloud or browser tunneling
BASE_URL and SKYVERN_API_KEY:
Start the local server
If you usedskyvern quickstart and chose to start services, Skyvern is already running. If you used skyvern init, start the server with:
Run locally
The only difference from cloud is thebase_url parameter pointing to your local server. The Page/Agent/Browser API is identical, so the same code works in both environments. Develop locally, deploy to cloud without changes.
/qa http://localhost:3000 in Claude Code to validate the app against your local environment.
Next steps
Build a Browser Automation
The full Page/Agent/Browser walkthrough: AI actions, Playwright selectors, and agent tasks
Actions Reference
Every page action and agent method with parameters and return types
Extract Structured Data
Define a schema to get typed JSON output from your automations
Handle Logins
Store credentials securely for sites that require authentication
Build Workflows
Chain multiple steps together for complex automations
Use Webhooks
Get notified when tasks complete instead of polling